
Using Threat Modelling as a Strategic Development Tool

Security roles in crypto need steady, methodical work. Figuring out the safety of a complex protocol is genuinely challenging, and effective threat modelling is a structured way to spot weak points early so you can fix them. It's a straightforward process that taps into what engineers and business folks know about risks and priorities to create a clear path toward a stronger product.
At OP Labs we have a large security team. Even with all our expertise, we don't always have a gut feeling about where to focus our security efforts. Threat modelling guides us and builds confidence in our releases.
In this article, I'll show you how we do threat modelling, so that you can also acquire confidence that you are addressing the right security gaps.
This process is designed to be accessible and engaging, especially if you enjoy learning new approaches and building skills. Let's begin.
How Threat Modelling Fits Into a Security Strategy
Let’s introduce a basic security model so that we know where threat modelling fits.
As we code a feature, we add layers of security measures. The most basic of these is full coverage unit testing. When you do unit testing there is the temptation to test only the happy path in which every actor does everything that is expected of them. That is testing that your code does what it should and we think of it as the important part.
When you unit test for full coverage, though, you are also testing that the feature doesn’t do what it shouldn’t do. You are checking that when some actor does something wrong, there is a controlled and expected outcome.
Often, during testing, you will identify that there is the risk that actors will do something unexpected, and you want to limit the damage of their actions to themselves, other actors, or your feature itself.
This process of controlling the unexpected is critical to securing an application. It is nearly impossible to know everything that can go wrong with a product, but by reducing the space for unexpected outcomes we greatly reduce the risk.
After unit testing, we regularly layer on more security measures. We do fuzz testing, symbolic execution, formal verification, audits, contests and bug bounties. All of these aim to discover new ways in which your feature would have an unexpected outcome.
But how do you know which security measures do you need? How do you know that you have enough of them? How do you know that they cover the right components? How do you know if you need to build a custom security measure?
The answer to that is threat modelling. That is how we feel assured that we have applied enough security measures in the right spots to reach the level of confidence that we need.
Brainstorming the outcomes
The best way to start threat modelling is by thinking what are the worse outcomes that could happen to the protocol. This is a list that often lives rent-free in the head of everyone working close to crypto security.
When I was working at Yield Protocol, our main concern was having the user assets stolen, but we also fretted about us dropping them in some unrecoverable location while transferring them from the user, and a number of other nasty outcomes.
Now at OP Labs, we worry first about the assets in the bridge, then the chains stalling for extended periods of time, and then other minor unpleasant outcomes.
Any list of negative outcomes is easily ranked from the worst outcome in descending order of damage, once you take the time to write everything down. Then you will start your threat modelling with the scariest outcomes, as they are the most likely to produce urgent mitigations to execute.
Building a tree of outcomes
Let’s build a threat model from scratch. First a small one and then a more complex one. There are many ways of building these, but in this article we will follow the very simple process we use at OP Labs.
Our threat models are trees. In each root node you have an outcome we want to prevent. Things like our bridge being drained or a chain halting long enough for our users to notice.
Stemming from each outcome we include all the events that could cause it. These are often component failures within the system, but they can also be external requirements of any nature.
In the following example for a very simple onchain permissionless exchange we have an outcome that we want to avoid, which is a pool being drained of its assets. We have arbitrarily divided the code on each pool in two components that are a payout function and a transfer function, as we understand that any of these two components failing could lead to the pools being drained.
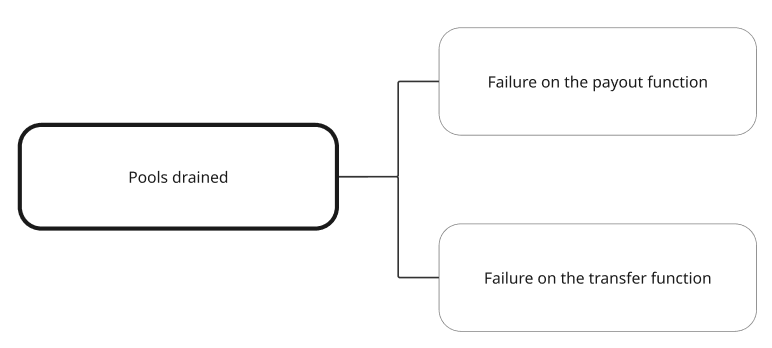
This is an arbitrary division, but that will do. Any partitioning of complex systems into simpler ones will help you in finding where the risk is, as long as the leaves don’t overlap. You should lean on the engineers that built the feature, which usually can explain it in terms of isolated components.
There are some missing components which we could have included as well. What if there is a bug in the underlying blockchain software? Feel free to include anything that you feel is relevant, later on you’ll find out if it is important.
To continue, let’s build a more complex tree. In this one we have an onchain tokenized vault that uses an external oracle to calculate the value of its assets, and we have decided that we should look into this component in more detail.
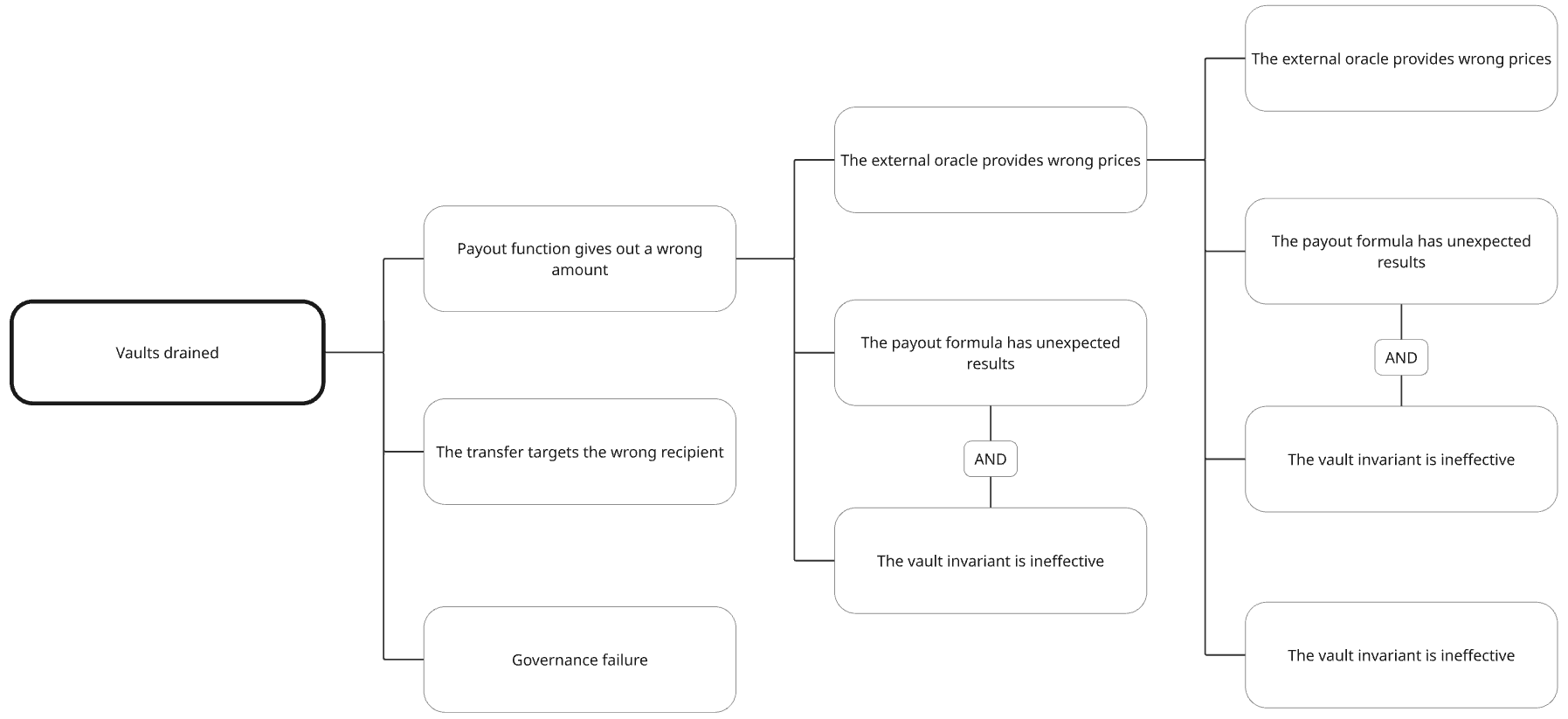
This one is more complex, but it is built in the same top-down approach, until we feel that we have gone down enough into specific components. Note that we can describe two components that would have to fail simultaneously for a higher level component to fail. This is common when some security features have already been implemented.
This tree can be read from the leaves as a cascade of component failures and external events that lead to an outcome that can be perceived by the users. The tree should be reasonably readable and descriptive. It should be easy to understand what is going on, and abstractions should not be abused.
For example you could say that a failure in the data processing under the external oracle would lead to the external oracle feeding incorrect data to the payout function, which could lead to the pools being drained.
In the example above if our math module fails, the invariant module would also need to fail in order for the payout function to misbehave.
You can build the tree in the upwards direction as well. You can take any isolated component and investigate what would happen if it fails. This component failure could cause failures of larger systems until it is noticed by the user, which is when you have reached an outcome. If there is a security measure that should catch this cascade of failures, add it as a node and assume that it also fails.
Whichever direction you build your tree from, and however you split your product into systems and components, you will end with a number of trees. For each tree you will have an outcome that you want to avoid, and a hierarchy of components whose failure would cause the outcome.
It can be the case that the same components and sub-trees are repeated if they lead to different outcomes. In those cases, we focus on the most severe outcome. Let’s see how to assess that.
Working out event likelihoods
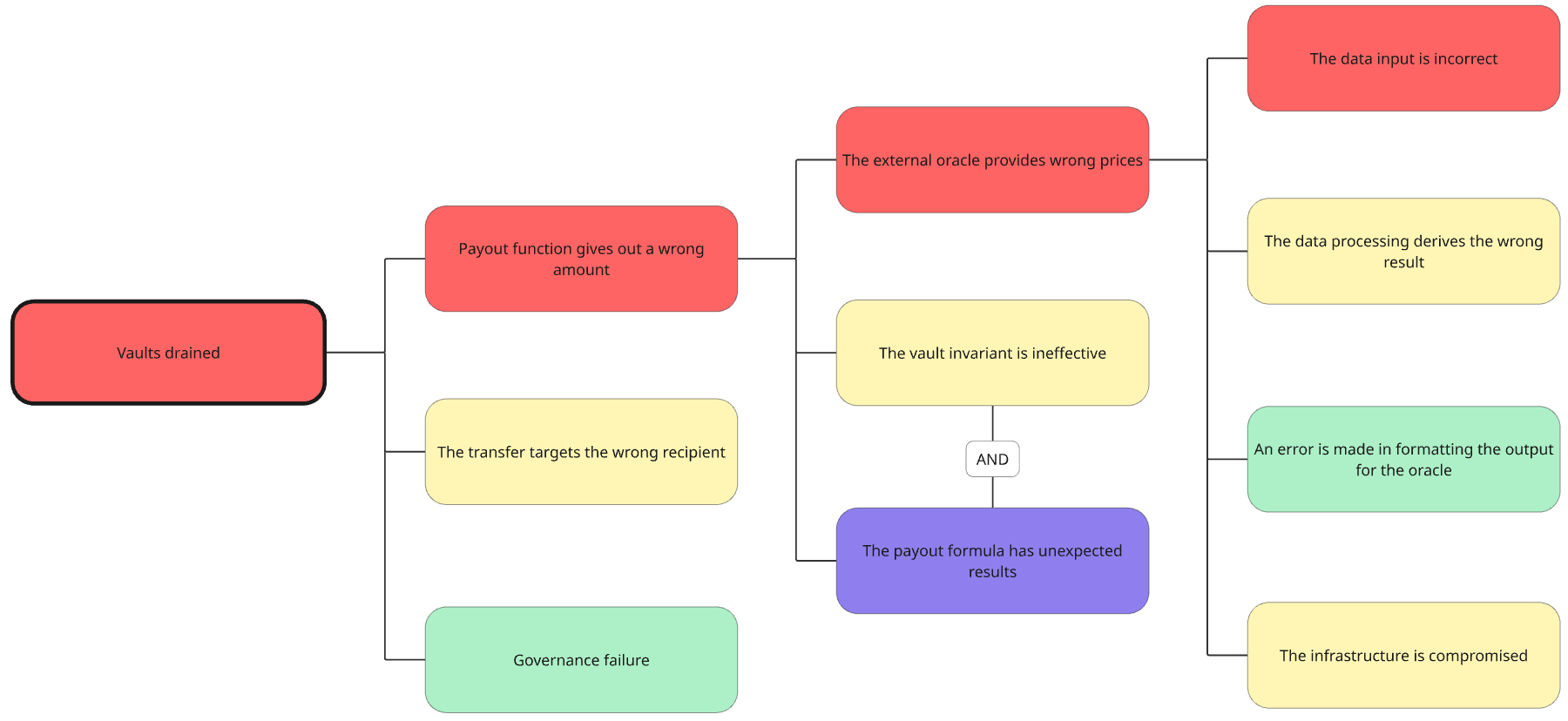
At OP Labs we use four levels of likelihood for each event:
- Certain to happen very soon (purple)
- Very likely to happen within one year (red)
- Might happen within two years (yellow)
- Unlikely to happen for several years (green)
It is difficult to have any certainty when assigning a likelihood to an outcome, but its often easier to reason about how much we understand the logic of a smaller component. The experts responsible for each part of a system can be pretty good at assigning likelihoods of failure to smaller components as long as it's made clear that being more or less right is enough.
The likelihoods are combined up the nodes of the tree to reach to the likelihood of the outcome. The likelihood of a node with two leaves of different likelihood takes the most likely of them if combined with the default OR, and the least likely of them if combined with an AND.
In the tree below, even if second-level nodes was purple, it was AND'd with a yellow node, so their combined likelihood is yellow, and overruled by the red coming from the third-level nodes. The outcome at the root will be at least red (very likely within one year).
How to avoid disaster
Now that we know how individual component failures lead to undesirable outcomes, we can focus on those and come up with mitigations.
In our example, let's imagine that we are happy if the vaults are not drained during the first year, because we know that by then we will have worked out a long-term plan. We need then to target those leaves with a likelihood of red or purple, of which we have two.
Let's say we ask the developers how to be safer, and they suggest implementing checksums for the red leaf, and formal verification for the purple leaf.
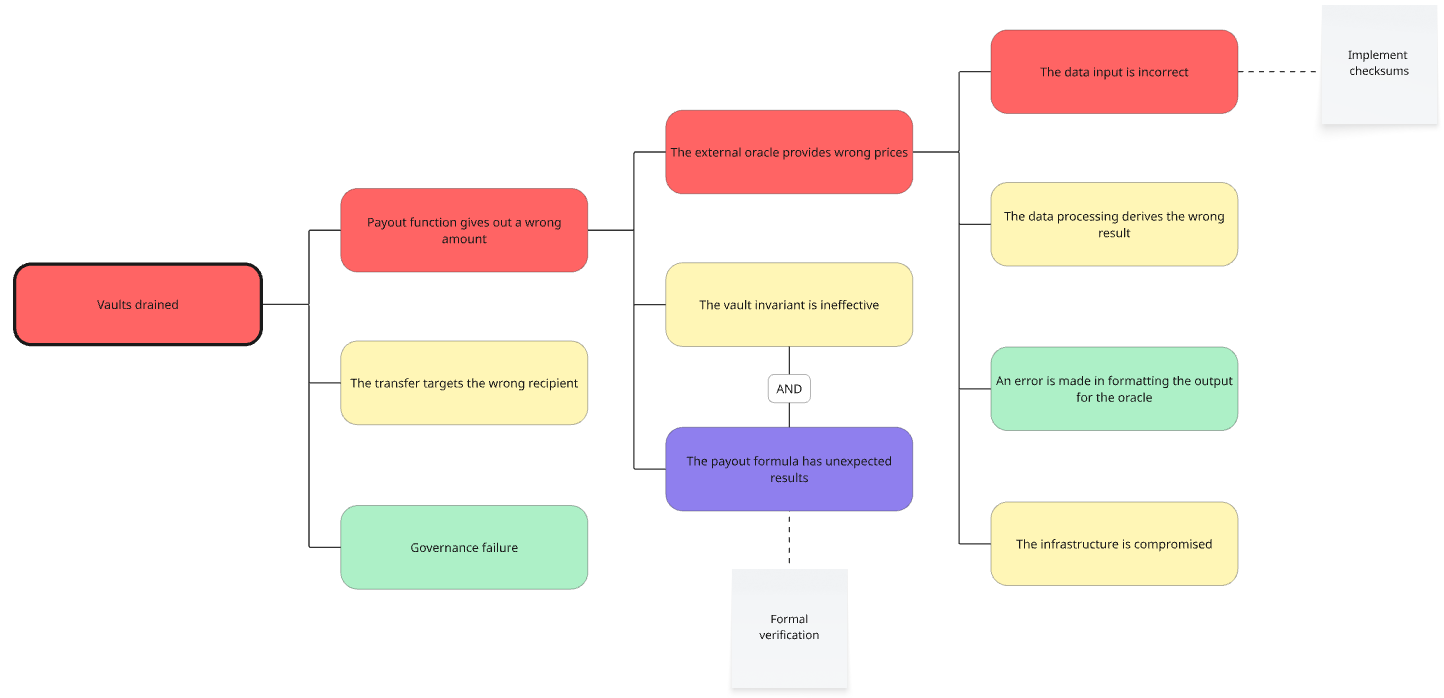
However, we know that the purple leaf is AND'd with a yellow leaf, so we don't need that mitigation. It seems that if we implement checksums we will reach the desired level of risk. This is the resulting tree:
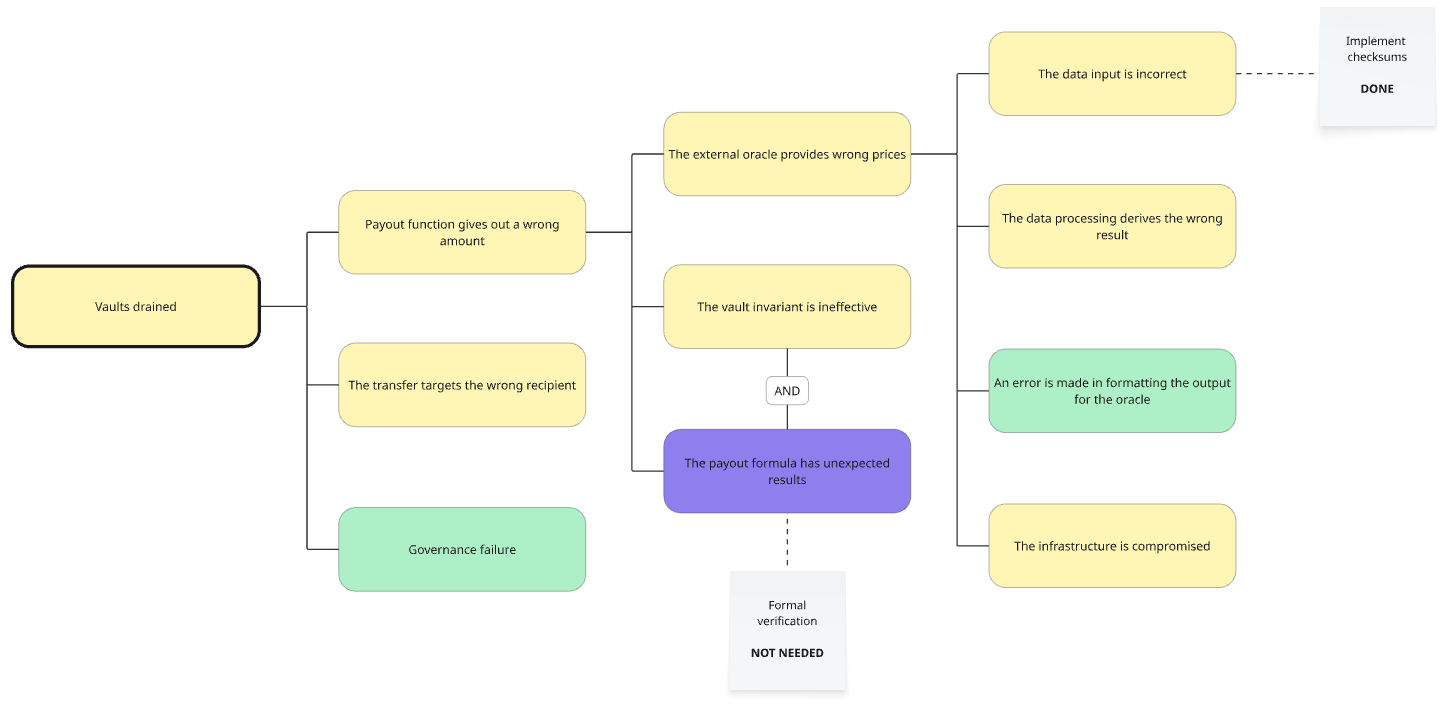
This process can be repeated until we have a work plan to reduce the risk of each outcome to the desired level of risk.
Conclusion
At OP Labs we have used variations of this threat modelling system for several releases already. After each threat modelling exercise we would identify components with an unacceptable risk and we would implement mitigations addressing those specific components.
We are using this process now for interop, which is possibly our most complex release ever. This threat modelling allows us to tap into the expertise of individual engineers working on their individual components to know where we stand down to the smallest components, and chart a path for a safe release.
We identified many distinct outcomes to avoid, and their combined threat trees had more than a hundred nodes. To bring down the likelihood any of those outcomes happening, we are implementing dozens of mitigations.
Using the process described in this article, you should be able to increase the certainty that you are working on the right things to release software safely, and that is good for all of us.
At OP Labs, we are hiring individuals ready to work at the bleeding edge of technology and security. If you want to work with a world-class team on world-class projects, get in touch!