
Lessons in Causality: Measuring Impact in the Superchain Ecosystem


Measuring Impact Is Hard
We all love a good story, especially in crypto, where rapid change and open data make it easy to find patterns and draw conclusions. An incentive program launches, and new addresses follow. A protocol upgrade goes live, and usage spikes. It’s tempting to attribute any shift in key metrics to the most visible intervention. But without a structured approach to measurement, these assumptions are fragile at best and misleading at worst.
These aren’t just academic questions, they go to the heart of how we allocate resources, design incentives, and evaluate outcomes. Getting these answers right is critical for the long-term success of the Collective, to ensure we’re rewarding the right builders and supporting contributions that drive sustainable ecosystem growth.
In a space as complex and fast-moving as crypto, correlation is often mistaken for causation. As Randall Munroe humorously captures in one of his xkcd comics, it’s easy to see patterns in data and assume they’re meaningful, even when they’re just coincidences.
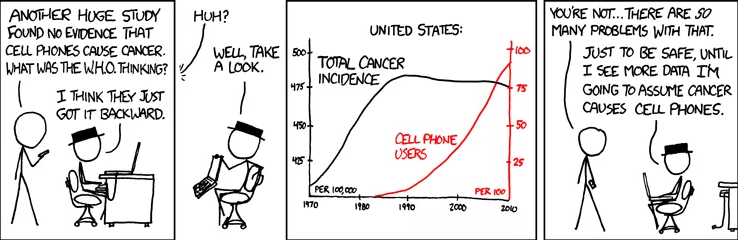
At the Optimism Collective, we take a deliberately experimental and causal mindset. We design measurement systems and run experiments to go beyond surface metrics so that we can iterate faster, make better decisions, and build what truly works.
Why Observational Data Alone Can Be Misleading
Imagine giving apples to elite athletes before an event, seeing they run fast and then concluding the apple made them so. But they were probably already fast to begin with. Without a proper counterfactual (what would’ve happened without the apple), we risk mistaking correlation for causation.
The same thing happens in crypto.
Take the example of an incentive targeting users based on their gas fee spending. In this simplified scenario, the x-axis represents gas fees paid, and the y-axis represents user retention. Suppose eligibility is based on crossing a certain gas fee threshold (in reality, criteria are often more complex). The goal is to evaluate whether receiving the incentive improves retention.
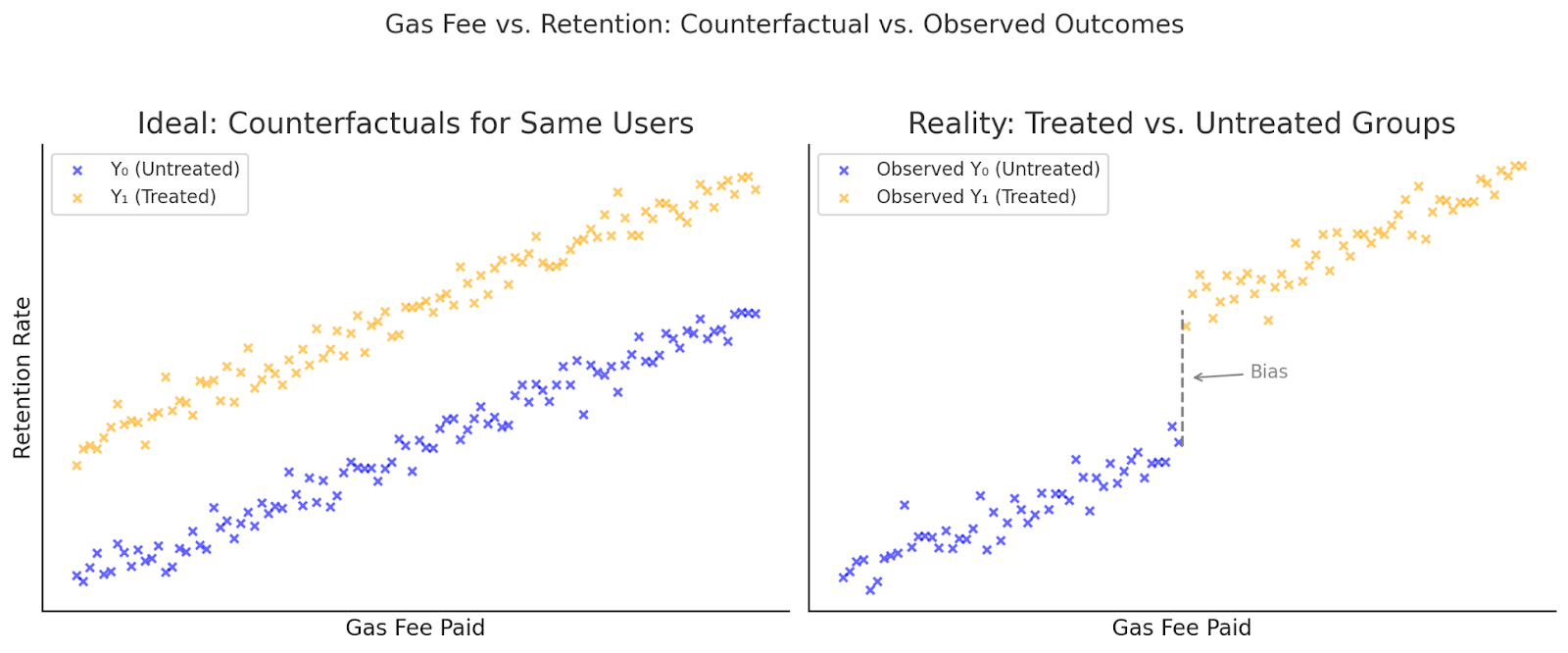
At first glance, it might look like users who spend more on gas also stick around longer, suggesting the incentive is working. But that relationship can be misleading. Those who cross the threshold are likely already more engaged and would’ve stuck around even without the incentive.
That’s selection bias: we’re comparing fundamentally different groups. The incentive may appear effective, but the observed impact could be entirely driven by pre-existing differences, not the program itself.
Causal Questions are Everywhere in the Superchain Ecosystem
While regression algorithms are great at identifying correlations and predicting growth trends, understanding why something happened is much harder. Yet causal questions are everywhere in the Superchain ecosystem. Here are a few examples:
While measuring causal impact is difficult, it’s a challenge worth tackling, and many other domains, from public policy that used randomized evaluation to save taxpayers millions of dollars, to tech companies that built non-experimental causal inference tools to measure the benefit of new tools, have faced and overcome.
We don’t need to start from scratch. We can draw from proven methods and real-world examples to build smarter, more accountable systems. To do that, we need a shared way of thinking about causality that’s both practical and accessible.
A Practical Framework for Causal Thinking
Measuring impact in open systems is difficult, but it becomes a bit easier when we approach it with the right mindset. Below is a practical framework for thinking causally, even when we can’t run perfect experiments.
Define the Objective and Measurement Upfront
Before anything, we should ask ourselves: “What’s the decision this is meant to inform?” This idea comes from the Experimentation Prioritization Framework at Optimism, which recommends focusing on experiments (or measurements) that directly inform actionable decisions.
Just as important is being explicit about how we’ll measure success. What metric(s) matter most for the outcome we care about—retention, growth, revenue, decentralization? Are we optimizing for a short-term spike, or long-term sustainability? Having a clear, shared definition upfront ensures our analysis aligns with what really matters.
It’s tempting to define measurement after an initiative is already live. Doing so opens the door to cherry-picking metrics or rationalizing outcomes after the fact. Instead, we should treat measurement design as part of the initiative itself: planned early, tightly aligned with the decision at hand, and baked into execution from the start.
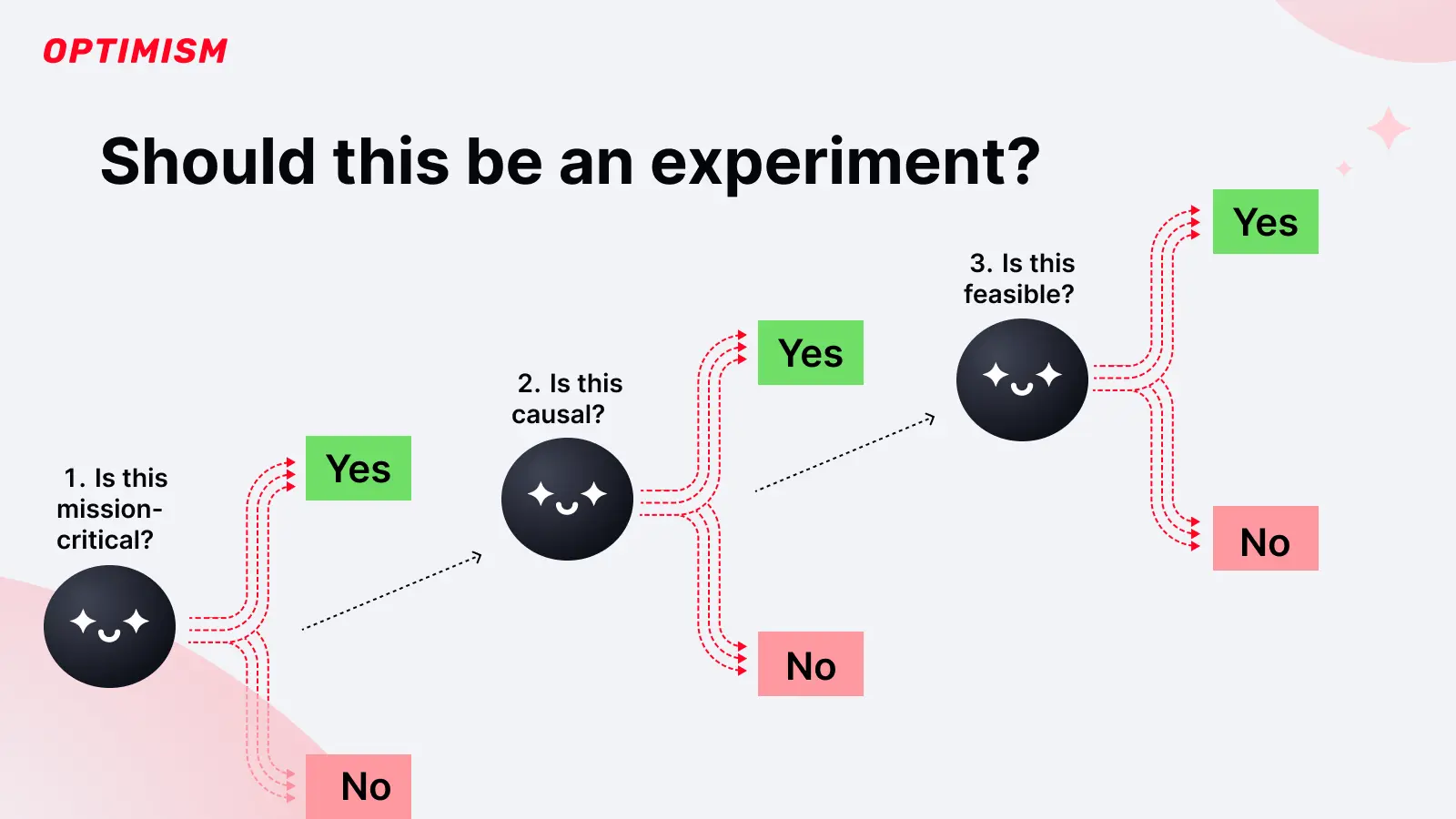
We can use the decision tree below to ensure our research topic and measurement efforts are actually useful.
When Randomization Isn’t an Option
In a perfect world, we’d run randomized experiments to cleanly isolate the effect of any intervention where possible. However, that’s rarely feasible in reality. Programs like airdrops, Retro Funding, liquidity mining and new feature launches affect the whole ecosystem at once, making it hard to create clean control groups.
Still, we can learn from structured observation. Methods like regression discontinuity or synthetic control help estimate impact when randomness isn’t possible. Even non-causal tools like descriptive trends, network analysis, sentiment tracking, and simulation can offer valuable insight when interpreted carefully.
The key is to choose the right method for the question, and to stay honest about what we can (and can’t) conclude.
There are many causal inference methods out there, each suited to different data and decision contexts. To help decide what approach to use, the chart below (while not exhaustive) outlines different analytical methods based on two factors:
(1) strength of causal inference, and (2) data requirements.
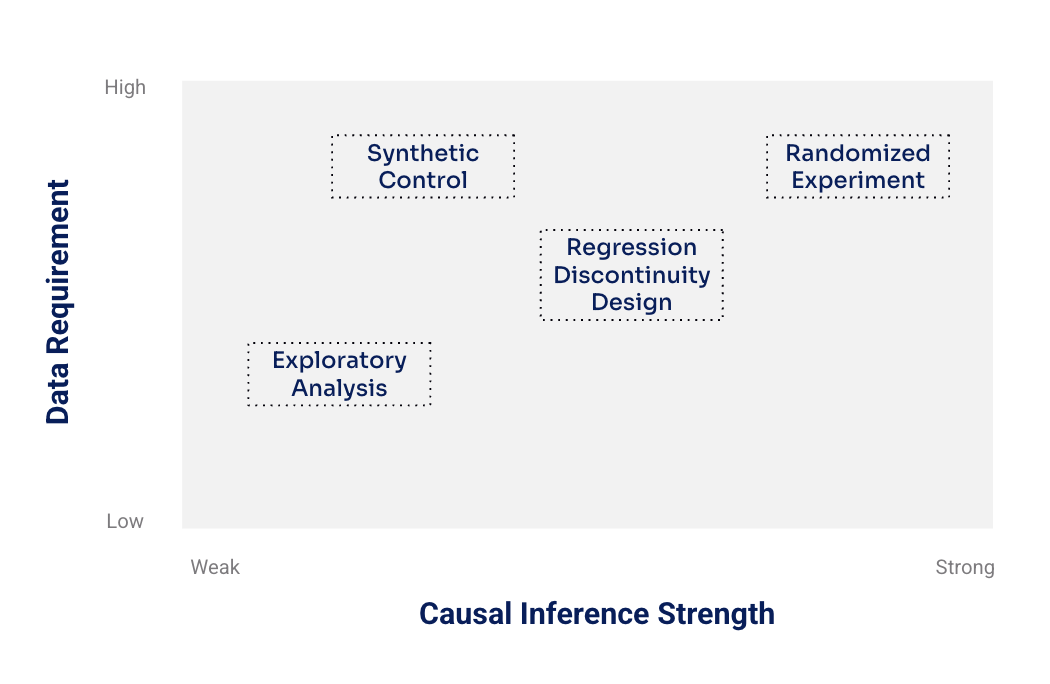
Here’s a quick guide to what these methods mean:
In the next section, we’ll walk through a few case studies from the Superchain ecosystem of applying different methods to asset impact and uncover insights.
Observations from the Superchain Ecosystem
While not every initiative is launched with experimental design in mind, we can still learn from them using thoughtful analytical approaches. Below are a few examples within the Superchain ecosystem where we’ve tried to better understand real impact, despite imperfect setups.
We will explain each of them in more detail below.
OP Reward Program Exploratory Analysis
We evaluated the effectiveness of OP reward programs across 3 seasons in OP Rewards Analytics Update. These programs varied in design, objective, and protocol, so instead of aiming for a unified causal estimate, we took an exploratory approach, analyzing performance during the incentive period and in the 30 days after program end. The goal was to identify and compare in terms of retention, usage and potential strategic tradeoffs across implementations. It’s important to note, however, that we cannot attribute the observed increases in TVL or usage solely to the reward program.
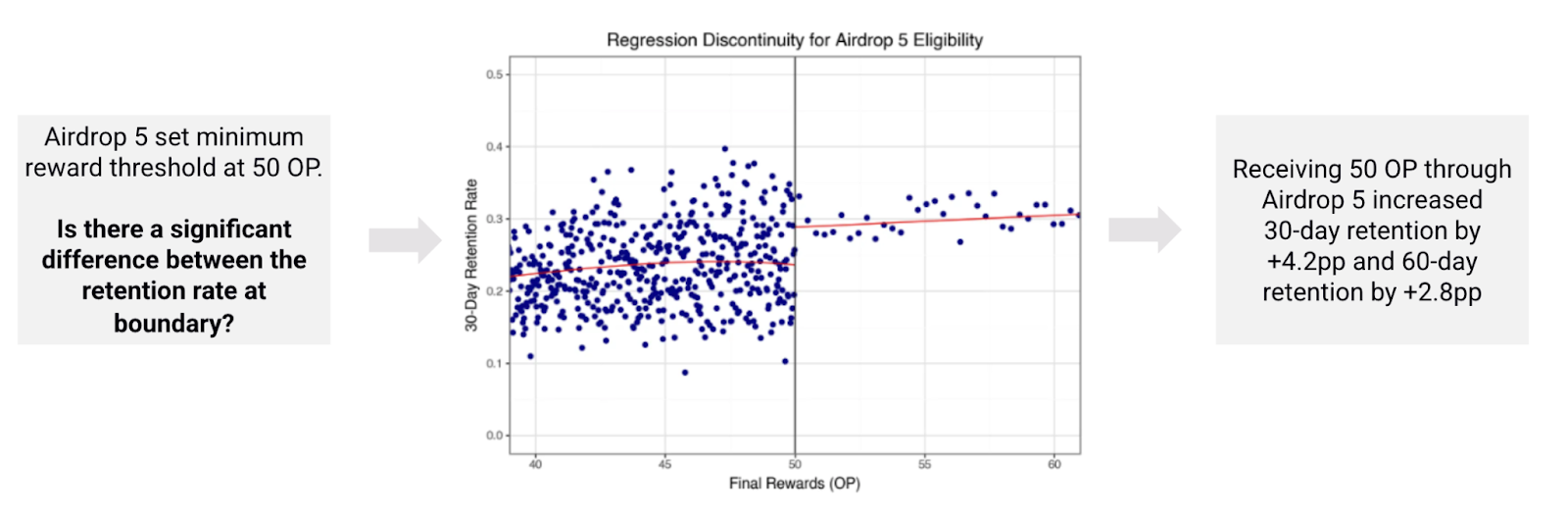
Airdrop Retention via Regression Discontinuity
To overcome the issue of confounding and to estimate the effect on addresses receiving airdrop 5 on subsequent retention, we used a regression discontinuity design to understand effectiveness of an intervention around an arbitrary threshold / boundary—in this case, addresses just above or below the 50 OP threshold.
The results suggest that receiving the airdrop led to a 4.2 percentage point (pp) increase in 30-day retention and a 2.8pp increase in 60-day retention, compared to similar addresses that did not receive the airdrop.
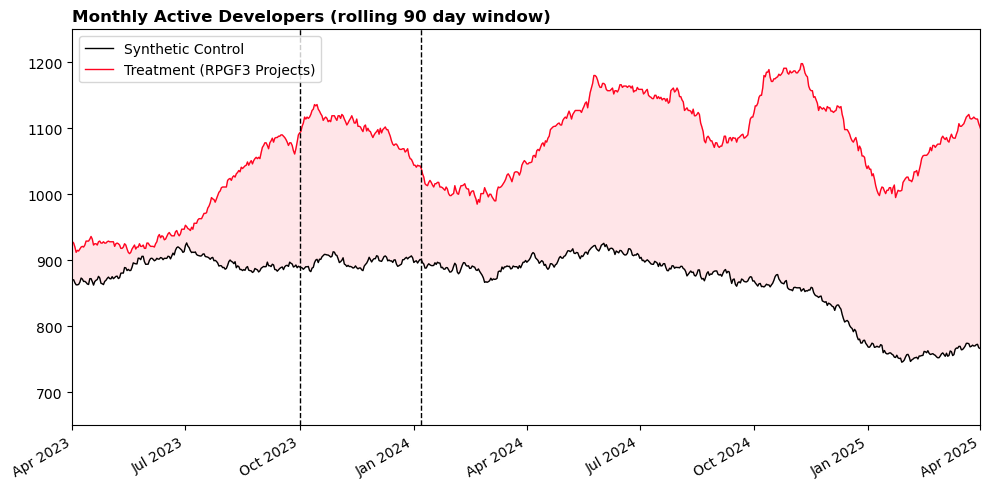
Measuring Retro Funding Impact with Synthetic Control
Open Source Observer (OSO) used synthetic control to estimate what would have happened to rewarded projects had they not received funding. By constructing a weighted composite of similar projects from peer ecosystems, we could use a counterfactual to compare actual outcomes against, offering a read on program effectiveness, despite the lack of randomization.
Final Words
The Optimism Collective should continue to apply these approaches across ecosystem programs, from incentive design to governance to developer funding. What makes crypto especially powerful is the ability to test and learn in real time. With massive amounts of public onchain data, we have a unique opportunity to study human behavior, coordination, incentive response and governance at scale, much like how big data transformed the way we understand and build for the internet today.
It's an ongoing process of iteration and learning, and each step brings us closer to developing a more robust and systematic approach to understanding what truly drives impact.